
北京软件外包公司研究语音信号处理增强语音转换模型
北京软件外包公司研究人员研究了一种使用自适应限制波尔兹曼机器的新的语音转换方法,该机器能够解构语音并重建它,使其听起来像一个不同的人说话。至关重要的是,这种模式不需要来自两位演讲者的并行数据进行训练,意思是目标声音可以说词和句子不用于训练。
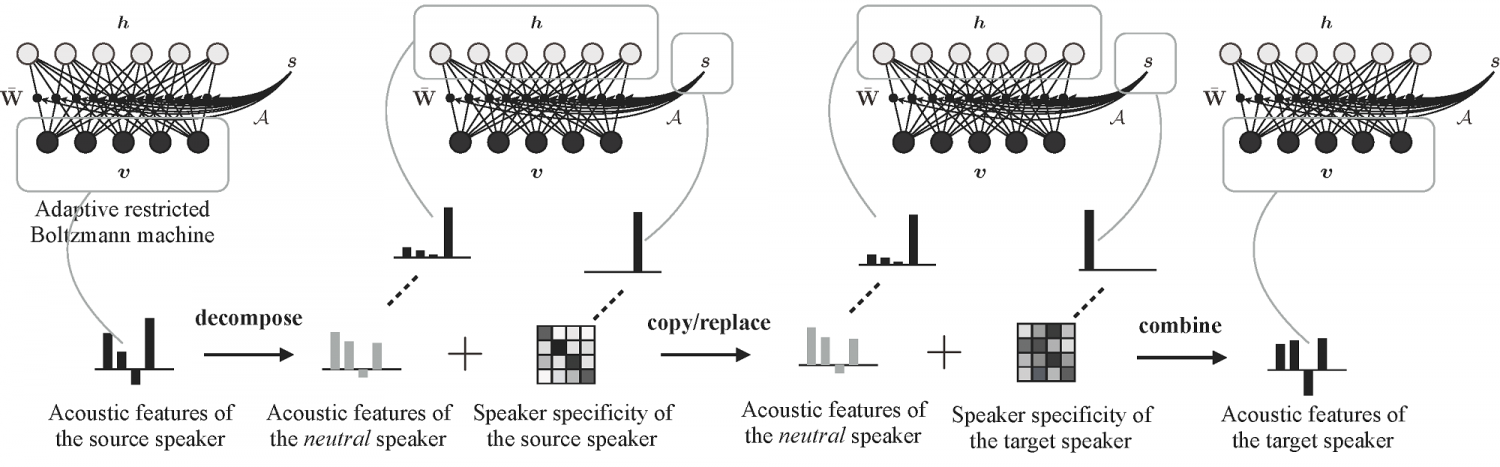
改变人的声音,使其听起来像另一个人是一种用于安全和隐私的有用技术,例如。这种称为语音转换(VC)的计算技术通常需要来自两个扬声器的并行数据来实现自然音调转换。并行数据需要录制两个人说相同的句子,具有必要的词汇量,然后进行时间匹配,并用于为原始演讲者创建新的目标声音。
然而,在语音处理中存在与并行数据相关的问题,尤其是两个扬声器之间的精确匹配词汇的需要,这导致缺乏未包含在预定义模型训练中的其他词汇的语料库。现在,东京电子通信大学的Toru Nakashika和同事已经成功地创建了一个能够使用非平行数据来创建目标语音的模型 - 换句话说,目标语音可以说句子和词汇不用于模范训练。
北京软件公司新的VC方法是基于简单的前提,即语音的声学特征由两层组成 - 属于没有特定人的中立语音信息,以及使扬声器身份特征使得声音听起来像是来自特定扬声器。Nakashika的模型称为自适应限制Boltzmann机器,有助于解构语音,保留中立的语音信息,但将演讲人的具体信息替换为目标扬声器的信息。
训练结束后,该模型与现有的并行训练模式与新的音素的声音可以为目标扬声器,这使得可以产生额外的好处可比演讲代目标讲话者用不同的语言。